OS-0606: File system imporved, Disk Management(L32, 33)
#(L32)Disk Hardware

- Seek time - 헤드 포지션을 잡는 시간
- Rotational delay - 헤드 밑에 원하는 섹터가 오는 시간
#Disk Access time
- 일반적 수치:
> 트랙 당 32~64섹터
> 1KB당 섹터
- 데이터 전송 속도는 초당 헤드 아래로 회전하는 바이트 수
> 1KB/섹터 * 32섹터/회전 * 120회전/초 = 4MB/s
- 디스크 I/O 시간 = seek+rotation delay+transfer
> seek = avg 5ms
> rotation = avg 4ms
> 1KB = 0.25ms
> I/O = 9.25ms/KB, 100KB/s정도
- 반면 메모리 접근은 20MB/s(200배 빠름)
#Selecting the Sector size
- read/write 헤드는 회전하는 동안 헤드와 동기화해야함
> 디스크 회전 속도 측정 위해 섹터 사이에 100~1000bit 필요
- 섹터가 1B인경우
> 디스크 유용한 데이터는 전체 디스크의 1% 차지
> 이전과 비교해 전송속도는 1/1000이므로 100B/s
- 섹터가 1KB인경우
> 디스크 유용한 데이터 90%
> 속도 100KB/s
- 섹터 1MB
> 거의 모든 공간이 유용한 데이터
> 속도 4MB/s(전체 디스크 전송 속도 -> seek, rotation delay 더이상 중요하지 않음)
#Evolution of UNIX Disk Management
- Berkeley BSD 4.0 UNIX:
> 블록 사이즈 1024B
> 성능 약 두배
> 각 블록 액세스는 두배의 데이터를 가져와 seek overhead 줄음
> inode의 direct만 사용할 수 있어 추가 공간 절약
> 파일 시스템 처음 생성시
> free list가 정렬됨, 이로 인해 175KB/s 의 전송속도
> 수 주 지나면서 데이터와 빈 블록이 무작위화되어 전송속도 30KB/s로 감소
> 최대의 4%
- 왜 블록이 커졌을까
> internal fragmentation을 야기
> 대부분의 파일은 작고, 아마 1블록
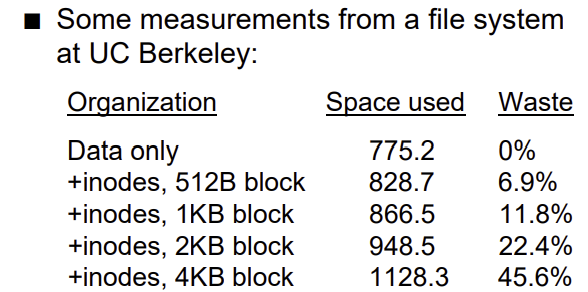
- 작은 파일의 존재는 큰 파일의 성능을 저하시킴
> 그러나 큰 파일의 오버헤드를 줄이기 위해 큰 블록 필요
> 큰 블록은 작은 파일의 fragmentation 증가시킴
#Improving Performance with good block management
- OS는 일반적으로 비트맵(비트의 배열) 을 사용해 빈 블록 추적
> 1: 빔, 0: 할당됨
- 디스크가 가득 차면 잘 작동하지 않음
> 해결: 디스크의 10%정도 여유공간으로 유지, 사용자에게 알리지 않음
#(L33)Improving Performance using a disk cache★
- 성능 향상을 위해 OS가 디스크 블록 캐시를 관리
> 주 메모리 일부를 캐시로 사용
> OS가 디스크에서 파일 읽을 떄, 해당 블록들을 캐시로 복사
> OS가 디스크에서 파일 읽기 전에 캐시 확인해 블록 있는지 확인 후(있으면 캐시 복사본 사용) 디스크에서 파일 읽음
- 블록의 대체 정책:
> 페이지와 동일한 옵션을 사용
> FIFO, 시계/두 번째 기회를 사용한 LRU
> 정확한 LRU를 구현하는 것은 간단
> OS는 블록을 읽을 때 업데이트 해야 할 모든 내용과 함께 '시간을 기록'하기만 하면 됨
> 그러나, sequential access는 LRU성능을 저하시킴
> 해결: 큰 순차적으로 액세스되는 파이레 대한 뒤쪽에 있는 블록을 캐시에서 제거(가장 옛날에 대화한 블록)하여 블록을 읽을 때 이전 블록을 캐시에서 제거
#Improving performance with disk head scheduling
- 디스크 요청의 순서를 변경
> 도착하는 순서대로
> seek 거리를 줄이는 순서
- 예시:
> 헤드가 트랙 30에 도달하기 위해 낮은 번호의 트랙에서 이동한 경우
> 요청 큐: 61, 40, 18, 78
- 알고리즘:
> FCFS(FIFO) = 30-61-40-18-78 로 헤드 움직임
> SSTF(가장 짧은 시크 시간(거리) 우선) = 30-40-61-78-61-18
> SCAN(0~100~0~100~반복) = 30-40-61-78-18
> C-SCAN(0~100, 0~100, 0~100 반복) = 30-40
> LOOK(90에서 찾는다고 가정하면 0~90~0) = 30-40-61-78-18
> C-LOOK
#Improving Disk Performance
- 일부 구조를 메모리에 유지
> 활성 inode, file table
- 효율적인 빈 공간 관리: bitmap
- 디스크 블록의 신중한 할당
> 가능하면 연속 할당
> 직/간접 블록
> 블록 크기의 적절한 선택
> 실린더 그룹
> 디스크 공간 일부를 여유 공간으로 유지
- 디스크 관리
> 디스크 블록 캐시
> 디스크 스케줄링
#Disk management
- Disk formatting
> 물리적 포메팅: 디스크를 헤더, 데이터영역, 트레일러로 나눔
> 대부분 디스크는 사전 포멧되어 있지만, 특수 유틸리티를 사용해 다시 포메팅 할수도
> 포메팅 후 디스크를 파티션으로 나눈 다음 파일 시스템의 데이터 구조를 기록해야함(논리적 포메팅)
- boot block(0번)에는 컴퓨터용 "bootstrap" 프로그램이 포함됨
> 시스템에는 이 프로그램을 로드하는 부트스트랩 로더가 있는 ROM도 포함됨
- 디스크 시스템은 불량 블록을 무시
> 디스크가 포멧되면 스캔이 불량 블록을 감지하고 디스크 시스템에 해당 블록을 파일에 할당하지 말라고 알림
> 디스크가 사용되는 동안에도 이 작업을 수행할 수 있음
- swap space management
> 일반 파일 시스템의 스왑 스페이스
> 별도의 파티션에 스왑 스페이스 -> 디스크 한쪽에 파티션 따로 만들어 스왑 전용으로 사용
> 하나의 큰 파일 - 전체 파일 시스템, 디렉토리 등이 필요하지 않음
> 블록을 할당/해제하는 관리자만 필요(속도 최적화)
- 디스크 신뢰성(reliability)
> 데이터는 일반적으로 영적구으로 간주됨
> Disk striping = 데이터를 블록으로 분할하여 연속적인 블록을 별도의 드라이브에 저장
> Mirroring = 전체 디스크의 "그림자" 또는 "미러" 복사본 유지
> Stable storage = 업데이트 중에 데이터가 손실되지 않음 -> 각 논리적 블록에 대해 두 개의 물리적 블록을 유지하고, 쓰기가 성공하려면 두 블록이 동일해야
*RAID(Redundant Array of Independent Disks)(0, 1, 5 만 알면 됨)
https://en.wikipedia.org/wiki/Standard_RAID_levels
-> 독립된 디스크를 여러개 두고 일부 중복된 데이터를 나눠 저장
- 0 = 디스크 2개, 오류검출(패리티) 없는 strip된 세트

- 1 = 디스크 2개, 오류 검출(패리티) 없는 mirroring된 세트

- 5 = 디스크 4개, 패리티가 배분되는 striping된 세트
