
OS-0606: File System(L29, 30, 31)
* 1File -> 하나의 inode(index node)를 가리킴
-> inode 1개당 13칸(앞 10칸은 direct disk data block을 지정 + single, double, triple indirect index)
* 1 Open file -> open file table에 저장
* per process file table -> open file table -> active index table
* Active file -> 어느 프로세스가 그 파일을 open 한 상태
#Disk Hardware

#Data structures for Files
- 각 파일은 파일 디스크립터에 의해 설명됨 -> 다음의 정보 포함(운영체제에 따라 다름)
> 포함: 유형, 액세스 권한, 링크 수(해당 파일 포함하는 디렉토리 수), 소유자, 그룹, 크기, 액세스 시간(생성된 시간, 접근한 시간, 수정된 시간), 디스크 상의 파일 위치가 있는 블록
> 불포함: 파일 이름
#OS Data Structures for Files
- Open file table(OS당 하나)
> 열린 파일을 리스트화
> 각 엔트리는:
> 파일 디스크립터
> 오픈 카운트 -> 그 파일을 오픈한 프로세스의 수
- Per-process file table(많음)
> 해당 프로세스가 연 모든 파일을 리스트화
> 각 엔트리는:
> 오픈 파일 테이블에 가기 위한 포인터
> 파일 내의 현재 포지션(offset)
#UNIX Data Structures for Files
- Inode table 활성화(하나)
> 활성된 인노드 리스트(파일 디스크립터)
- open file table(하나)
> active inode table 접근 포인터
> 파일 내 현재 포지션
- Per-process file table(많음)
> open file table 접근 포인터
#Disk Data Structures for Files
- 파일 디스크립터 정보는 지속성을 위해 디스크에 저장돼야 함
> 이전 슬라이드에서 나열된 기본 정보 모두 포함
> 모든 inode(파일 디스크립터)는 list라고 불리는 디스크의 고정크기 배열에 저장
> ilist의 크기는 디스크 초기화시 결정
> 배열에서 파일 디스크립터의 인덱스를 해당 파일의 inode번호 또는 inumber라고 함
- 파일 디스크립터는 다음과 같이 저장
> 처음에는 내부(또는 외부) 트랙에 함께 저장
> 그 다음 중간트랙에 함께 저장
> 현재: 작은 파일 디스크립터는 디스크 전체에 분산되어 파일 데이터에 더 가까워지도록 저장됨
#UNIX File System
- 파일 디스크립터(inode)는 파일을 나타냄
> 모든 inode는 ilist라불리는 고정 크기 배열에 디스크에 저장
> ilist 배열의 크기는 디스크를 초기화시 결정
> 배열에서 파일 디스크립터의 인덱스를 해당 파일의 inode번호 또는 inumber라고 함
> 활성 파일에 대한 inode는 active inode table에서도 캐시됨
- UNIX 디스크는 각각의 파티션으로 나뉠 수 있으며, 각 파티션에는 다음이 포함
> 디렉토리와 파일 저장 블록
> ilist 저장 블록
> 파일에 해당하는 inode
> 일부 특수 inode
> Boot block(0번): 시스템 부팅을 위한 코드
> Super block(1번): 디스크의 크기, 사용 가능 블록 수, 사용 가능 블록 목록, ilist의 크기, ilist내의 사용 가능 inode 수 등
#추가 메모★시험나온대(inode = index node, ilist = inode list)
inode내에 인덱스 13개(0~12번)(1 file 당 1 inode)
0, 1은 특수 inode, 2번부터 root directory
*가정: 1 데이터 블락 = 1KB, 32bit 시스템 -> 256개(1KB / 4 = 256)
direct index = 디스크의 블록을 직접 가리킴(앞 10개, 0~9번 정도)(10KB 저장)
single indirect index = 디스크의 블록을 가리키는데 그 블록은 다른 블록의 주소들을 포함(1개)(256 KB)
double indirect index = 디스크의 블록 -> 다른 주소 블록 -> 다른 주소 블록(1개)(256*256)
triple indirect index = 세번 거침(1개)(128^3)
즉, 하나의 inode는 10(다이렉트)+256(싱글)+256*256(더블)+256*256*256(트리플)KB
-> indirect 가 거치는 블락은 일반 데이터 블락하고 똑같이 생겼는데 index table이 들어가 있는 것
-> 이렇게 나눈 이유는 파일 사이즈 떄문
★디렉토리도 파일이다. => 파일 안에 다른 파일이 있을 뿐
*2번 노드(루트) 안에 13개의 index -> direct index를 따라 가서 나온 블록에 루트 디렉토리의 내용이 있음
*루트 디렉토리에 저장된 정보 == 하위 디렉토리의 inode 정보
#Working with Directories
- UNIX에서 디렉토리 탐색:
> 파일 이름이 "/"로 시작하면 파일 시스템 트리의 루트(inode 2)에서 시작
> "~"로 시작하면 홈 디렉토리
> 다른 문자로 시작하면 현재 작업 디렉터리
- 작업 디렉터리
> 파일 이름은 "/"로 레벨을 구분하여 전체 경로 이름으로 지정
> UNIX는 각 프로세스의 현재 작업 디렉토리의 inode 번호를 추적. 전체 이름을 사용할 필요 없음
- UNIX 디렉토리의 두 가지 특수한 항목
> "."는 디렉토리 자체
> ".."는 상위 디렉토리
#Working with Directories(Lookup)★
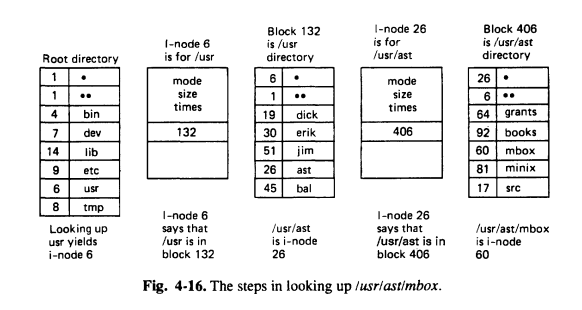
- 디렉토리는 엔트리의 테이블
> 2B = inumber
> 14B = file name
- 탐색 두가지 -> 루트에서 시작 or 현재 작업 디렉토리에서 시작
> inode 2 는 루트 디렉토리 가리킴
> 위 사진에서는 /usr/ast/mbox
* inode 2 -> 루트 디렉토리의 내용(데이터 블락) -> inode6번(usr 엔트리) -> 132번지(usr directory 내용) -> 26번(ast 엔트리) -> block 406(ast의 내용)
#Working with Directories(Links)
- 링크를 지원 = 동일한 파일 포함하는 두 개의 디렉토리 가능
- 하드링크("in target_file directory")
> 지정된 디렉토리는 대상 파일을 참조
> 두 디렉토리는 동일한 inode 가리킴
> inode 내의 링크 카운트는 해당 파일이 마지막으로 참조하는 디렉토리 항목이 제거될 때 까지 파일이 삭제되지 않도록 보장
- 소프트/심볼릭 링크("in -s target_file directory")
> 지정된 디렉토리에서 대상 파일(또는 디렉토리)로의 포인터를 추가
> inode에 특수 비트 설정, 파일은 링크된 파일의 이름만 포함
> "Is -F" 및 "ls -l"로 심볼릭 링크 확인
> 디스크 드라이브를 가로지르는 링크를 생성 가능

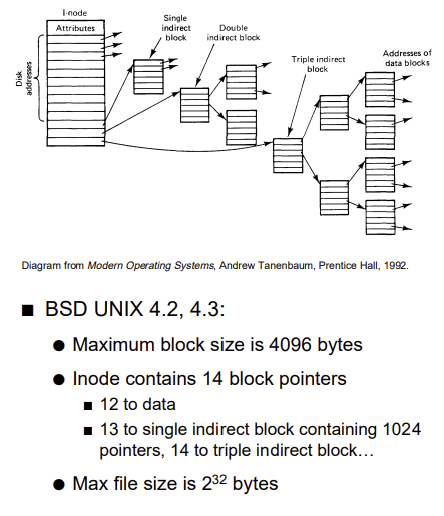
#Organization of Files(Multilevel indexed Allocation)
- 각 inode는 13 블록 포인터 가짐
> 첫 10개는 데이터 블록을 가리킴(direct)(each 512B long)
> 10 block보다 더 큰 사이즈의 파일은 -> 11번 single indirect block(128 추가 데이터 블록을 가리키는 포인터 128개)
> 더크면 12번 더블 인다이렉트 -> 128개의 single indirect 블록을 가리킴
> 더크면 13번 트리플 인다이렉트 -> 128개의 더블 인다이렉트 가리킴
#(L29) File System Issues
- user 입장
1. 지속성 - 데이터는 전원이 꺼지거나 시스템 충돌해도 유지
2. 사용 편의성 - 데이터 쉽게 찾고 검토, 수정
3. 효율성 - 디스크 공간 효율적 사용
4. 속도 - 데이터에 빠르게 액세스
5. 보호 - 타인이 손상, 또는 볼수도 없게 함
- OS가 제공하는 기능:
1. 디렉토리, 네이밍 있는 파일 시스템 - 디렉토리와 이름 지정하여 디스크 위치 대신 파일을 지정
2. 디스크 관리 - 파일이 디스크 상에서 어디있는지 추적, 빠르게 접근
3. 보호 - 무단 액세스 방지
#User interface to the file system
- 파일은 저장의 논리적 단위
1. 레코드의 연속
2. 바이트의 연속
3. 리소스 포크와 데이터 포크(맥킨토시)
> 리소스 포크 - labe, message
> data fork = code, data
- 저장되는것
1. C++소스, 오브젝트, 실행, 쉘스크립트, post script 등
2. mac은 파일 유형을 명시적으로 지원 - text, pict등
3. 윈도우는 파일 네이밍 규칙 - .exe, .com 등
4. UNIX는 내용 확인하여 유형 결정
> 쉘 = #로시작
> postscript - "%!PS-Adobe.."로 시작
> 실행파일 - 매직넘버로 시작
#File operations
1. Create(name)
- 새로 생성된 파일을 나타내기 위해 디스크에 파일 디스크립터 생성
> 디렉토리에 이름과 해당 파일 디스크립터를 연결하는 항목을 추가
- 파일을 위해 디스크 공간 할당
> 파일 디스크립터에 디스크 위치 추가
2. fileId - Open(name, mode)
- file id라고 불리는 고유 식별자 할당(유저에게 리턴)
- 파일에 대한 동시 액세스 제어 -> r, w, rw 설정
3. Close(fileId)
- 파일 닫기
4. Delete(fileId)
- 파일 제거 -> 제거 해도 블락 할당이 없어질 뿐 디스크 내에 데이터는 남아있음. 해당 블록에 다른 내용이 저장되어야 원래 있던 파일이 완전 삭제됨
5. Read(fileId, from, size, bufAddress)
- 랜덤 액세스
- fileId에서 from부터 시작하여 size바이트를 bufAddress에 지정된 버퍼로 읽음

6. Read(fileId, size, bufAddress)
- 순차 액세스
- fileId에서 현재 파일 위치인 fp에서 시작해 size바이트를 bufAddress에 지정된 버퍼로 읽어온 다음 fp를 size만큼 증가
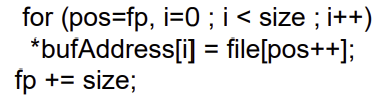
#Common file access pattern
1. 순차 액세스(sequential access)
- 데이터는 순서대로 한 번에 한 바이트씩 처리되며 항상 앞으로 진행
- 대부분 이 형태 ex: 컴파일러가 소스파일 읽기
2. 직접/임의 액세스(random access)
- 이전 데이터를 액세스하지 않고 파일 ㅐㄴ의 아무 바이트나 직접 액세스
- ex: 데이터베이스 레코드 12에 접근
3. 키 기반 액세스(keyed access) - 제껴도 됨, 안씀, 안나옴
- 키 값에 따라 바이트에 액세스 ex: db검색, 사전
- 운영체제는 키 기반 액세스 지원 x
- 유저 프로그램은 키로부터 주소를 결정한 다음 파일로의 random accesss(OS제공) 사용
#Direcotries and Naming
1. Directories of named files
- user 및 os는 디스크에 저장된 파일을 참조할 방법이 필요
- os는 번호를 사용하려 함(파일 디스크립터 배열의 인덱스)
- 유저는 텍스트 이름(가독성)
- os는 이름과 해당 파일 인덱스 추적 위해 디렉토리 사용
2. Simple naming
- 전체 디스크에 대한 하나의 이름 공간(싹 다 루트에 들어간거)
> 모든 이름 고유해야 함
- 구현:
> 디스크에 디렉토리 저장
> 디렉토리는 <이름, 인덱스> 쌍을 포함
- 초기 메인프레임에서 사용(mac, ms dos)
3. user based naming
- 각 사용자에 대한 하나의 이름 공간
- 해당 사용자의 디렉터리 내의 모든 이름은 고유, 두 사용자는 서로 다른 디렉토리에 동일한 이름 사용 가능
4. multilevel naming
- 트리 구조로 구성된 이름 공간
- 구현:
> 파일과 마찬가지로 디스크에 디렉토리 저장
> 각 디렉토리는 순서 없이 <이름, 인덱스> 쌍을 포함
> 디렉토리가 가리키는 파일은 또 다른 디렉토리일 수도
> 이름은 레벨을 구분하는 "/"를 가짐
> 결과적인 구조는 디렉토리의 트리로 이루어짐
> UNIX에서 사용